pacemaker和Corosync的安装与配置
Pacemaker 简介
Pacemaker 是一个开源的高可用性集群资源管理器,主要用于 Linux 系统环境,旨在确保关键服务和应用程序在发生故障时能够自动恢复或迁移,从而实现业务连续性。
核心功能
资源监控:持续监控集群中服务、应用程序、文件系统等资源的运行状态
故障转移:当某节点发生故障时,自动将资源迁移到健康节点
资源调度:根据策略(如优先级、位置约束)决定资源在哪个节点运行
集群协调:与底层集群通信层(如 Corosync)配合,维护集群成员关系和状态同步
典型架构组成
1 | |
Corosync
底层消息系统, 主要用来给集群中的各个节点进行可靠的消息传输。实时的检测那些节点在线\离线。通过心跳机制判断节点是否存活。
Pacemaker、Corosync配置实现
| 主机名 | IP 地址 | 角色/用途 |
|---|---|---|
| node1 | 10.201.9.133 | Web 服务器 |
| node2 | 10.201.9.140 | Web 服务器 |
1、修改主机名配置解析
node1
1 | |
node2
1 | |
2、校正服务器时间并强制同步。
node1
1 | |
node2
1 | |
3、安装pacemaker和 corosync相关组件
node1 & node2
1 | |
PCS 是 Pacemaker 集群的官方命令行配置与管理工具,它简化了 Pacemaker + Corosync 集群的配置、监控和维护操作。
pcsd 是 PCS(Pacemaker 配置系统)的后台守护进程,为集群提供配置管理、节点认证和 Web 管理界面支持。
设置集群用户的密码
hacluster 是 Linux 高可用集群(Pacemaker + Corosync)中专用的系统级服务账户。两个节点都保持密码是一致的。
1 | |
4、 创建集群
在创建集群之前,先使用命令检查下两个节点的hacluster密码是否正确
1 | |
Authorized认证是正常的。注意这里pcs cluster是centos7中使用的命令,如果是centos8的话,需要使用pcs host
- 创建并启动一个名为my_cluster的集
在任意节点上执行
1 | |
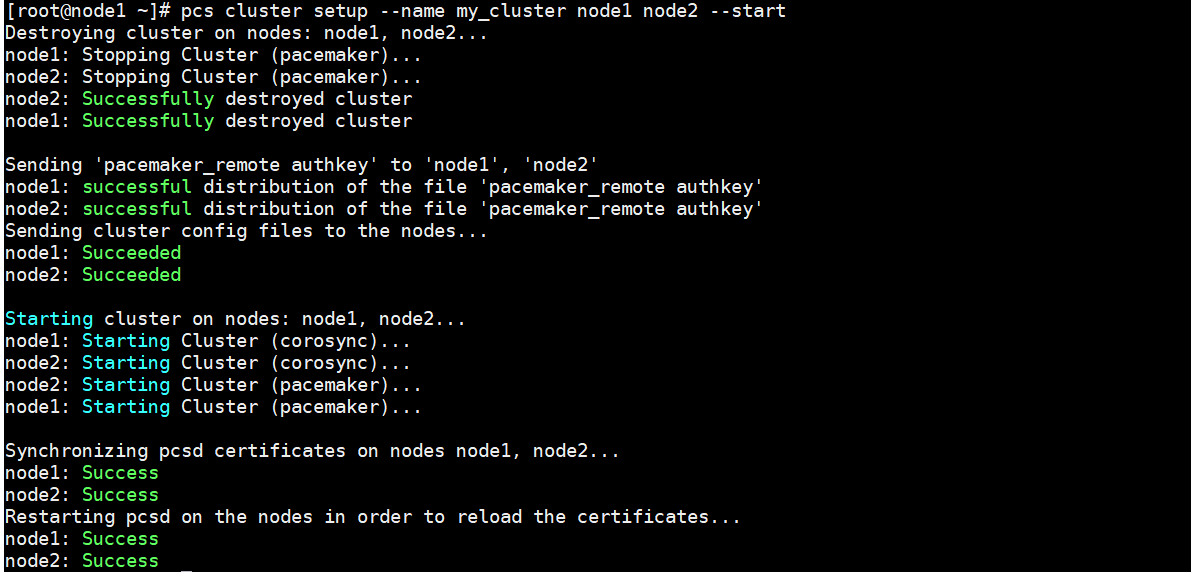
集群创建完毕之后,系统会自动生成一个名为corosync.conf的配置文件。
1 | |
- 启动集群并设置开机自启。
1 | |
5、 查看集群状态
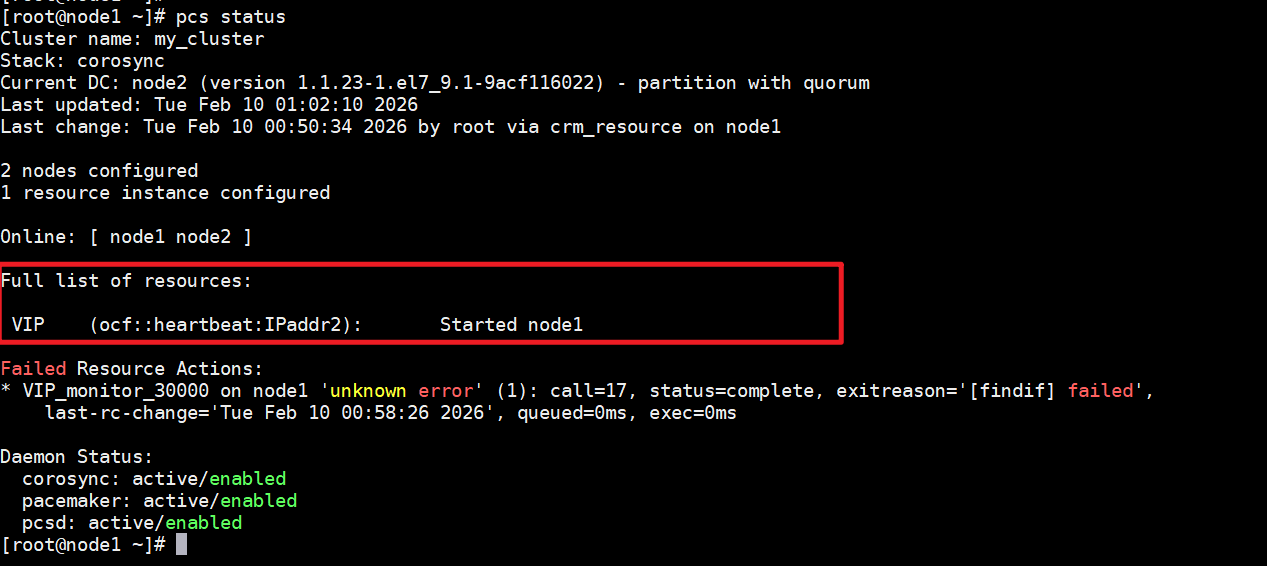
命令:pcs status
1 | |
命令 corosync-cmapctl | grep members 查看集群成员详细信息
1 | |
| 字段 | 含义 |
|---|---|
| members.1.config_version | 节点持有的配置版本号用于一致性校验 |
| members.1.ip | 节点1的IP地址 |
| members.1.join_count | 节点加入集群的次数,重启后递增 |
| members.1.status | 节点状态 joined(已加入集群),left(已离开,failed(故障) |
6、 集群初始化配置
命令crm_verify -L -V 详细验证当前集群的活跃配置,这条命令会检查xml语法是否合法,配置是否正常。以及STONITH 配置是否符合安全策略(默认要求启用)。
执行该命令检查的时候,会发现出现error,这个报错的原因是Pacemaker 集群的安全保护机制触发,未配置STONOTH(节点隔离)机制、但是集群默认要求启动。
STONOT是什么
STONOT是高可用集群的中的节点隔离机制,当集群节点失联时,通过物理/逻辑手段强制关闭故障节点,防止脑裂导致的数据损坏。
脑裂(Split-Brain)场景演示
注:下面的mermaid流程图是参考通义千问生成的
graph TB
subgraph 正常状态
A[节点1 + 节点2]
B[共享存储]
A -->|正常通信| B
end
C[网络故障/心跳中断] --> D{节点1视角}
C --> E{节点2视角}
D --> F["节点2已宕机"]
E --> G["节点1已宕机"]
F --> H[节点1挂载存储写入数据]
G --> I[节点2同时挂载存储写入数据]
H --> J[文件系统损坏]
I --> J
这里使用共享存储来举例子,节点1和节点2为一个集群访问同一个共享存储,当因为网络故障节点1和节点2出现了心跳中断的现象,节点1和节点2都会认为对方已经宕机了,那么就会出现节点1和节点2同时抢占一个共享资源,并写入数据而导致文件系统损坏。
STONITH 如何工作
隔离流程(以双节点集群为例)
sequenceDiagram
participant N1 as 节点1(健康)
participant N2 as 节点2(失联)
participant S as STONITH设备
participant R as 共享资源
N1->>N2: 心跳检测(3次超时)
Note over N1: 判定N2故障
N1->>S: 发送隔离指令(“关闭N2”)
S->>N2: 执行断电/关机
Note over N2: 物理断电(5-30秒)
N1->>R: 安全接管资源
N1->>R: 挂载存储/启动服务
本次实验不需要,可以将STONITH先禁用掉。命令pcs property set stonith-enabled=false,禁用之后就不会报错
票选机制
如果是偶数台服务器,那么票选机制是可以关闭的命令如下:pcs property set no-quorum-policy=ignore
集群故障时候服务迁移
当节点故障的时候,将节点上的服务切换至正常节点,一般默认是开启的,命令:pcs resource defaults migration-threshold=1
可选设置项:
置所有资源的默认粘性值为 100。
命令pcs resource defaults resource-stickiness=100,防止资源在节点间频繁跳动,资源一旦在某节点启动,除非该节点故障,否则不会因为其他节点分数变化而迁移。
查看当前配置的所有资源默认属性
命令:pcs resource defaults
设置集群中所有资源操作的全局默认超时时间
命令:pcs resource op defaults timeout=90s,资源操作主要包括启动资源、停止资源和健康检查。
配置资源操作行为
命令:pcs resource op defaults
1 | |
7、 为集群服务器配置集群资源(例如vip)
列出当前系统中所有可用的资源代理
命令:pcs resource list,资源代理指的是Pacemaker用来管理特定服务/应用的脚本或程序。
过滤资源类型pcs resource list ocf:heartbeat
可以看到支持ocf标准的代理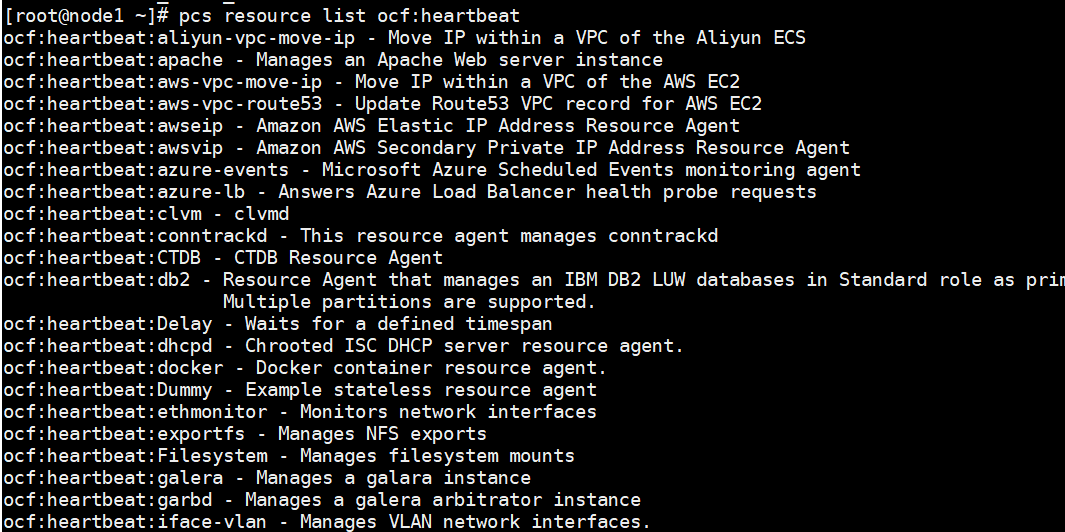
查看资源使用参数
以nginx为例
命令:pcs resource describe ocf:heartbeat:nginx,可以看到在创建nginx资源的时候可以使用的参数。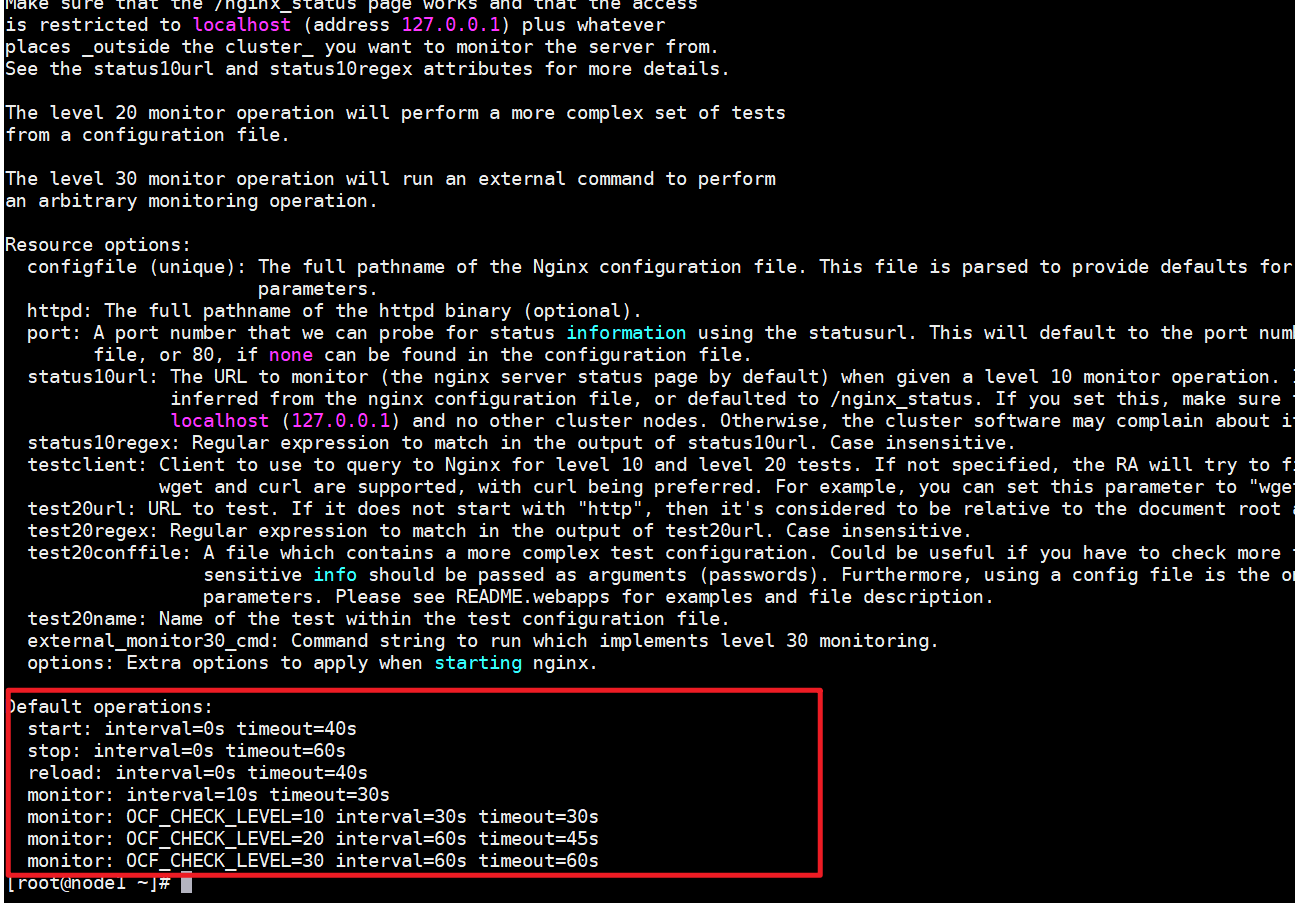
列出当前 Pacemaker 集群支持的所有资源标准类型
资源代理分类体系的基础命令。
命令:pcs resource standards,可以看到支持四种资源代理的类型
创建一个以ocf代理的VIP
在这里,我使用10.201.9.199做为vip,并且告诉集群,每30秒检查一次。
命令:pcs resource create VIP ocf:heartbeat:IPaddr2 ip=10.201.9.199 cidr_netmask=24 op monitor interval=30s
1 | |
| 参数段 | 说明 | 详细解释 |
|---|---|---|
pcs resource create |
资源创建指令 | Pacemaker 标准资源创建命令 |
VIP |
资源名称 | 自定义标识符(集群内唯一),建议使用大写+下划线命名规范 |
ocf:heartbeat:IPaddr2 |
资源类型 | • ocf:Open Cluster Framework 标准• heartbeat:提供者(Provider)• IPaddr2:资源代理名称(支持 IPv4/IPv6) |
ip=192.168.1.23 |
必需参数 | 虚拟 IP 地址(必须与业务网络同网段) |
cidr_netmask=24 |
可选参数 | 子网掩码(24 = 255.255.255.0),默认值 32(单机模式) |
op monitor interval=30s |
操作定义 | 添加监控操作:每 30 秒检查 VIP 是否存活 |
为无状态服务(如 Web 服务器、负载均衡器)提供单一访问入口,实现故障自动切换。
故障切换过程:
sequenceDiagram
participant C as 客户端
participant N1 as 节点1(故障)
participant N2 as 节点2(健康)
participant R as VIP资源
C->>N1: 访问 192.168.1.23
N1-->>C: 无响应(节点宕机)
Note over R: Pacemaker 检测到节点1失联
R->>N2: 在节点2启动 VIP
N2->>N2: ip addr add 192.168.1.23/24 dev eth0
C->>N2: 访问 192.168.1.23
N2-->>C: 正常响应(切换完成)
查看资源配置定义
命令:pcs resource show
查看完整资源配置
命令:pcs resource show --full
1 | |
通过以上两条命令可以看到,我们刚刚创建的资源VIP以及他的配置信息
查看完整集群状态
命令:pcs status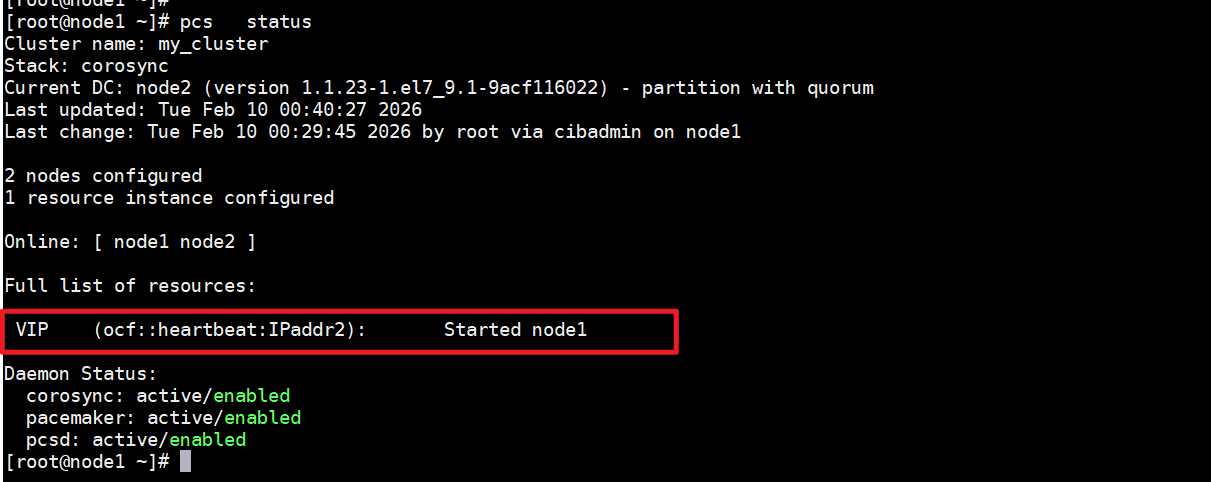
现在在查看集群状态,可以发现在状态中多了一个,VIP的资源并且是在node1节点上启动的。使用ip add可以看到在node1节点上会多一个IP地址。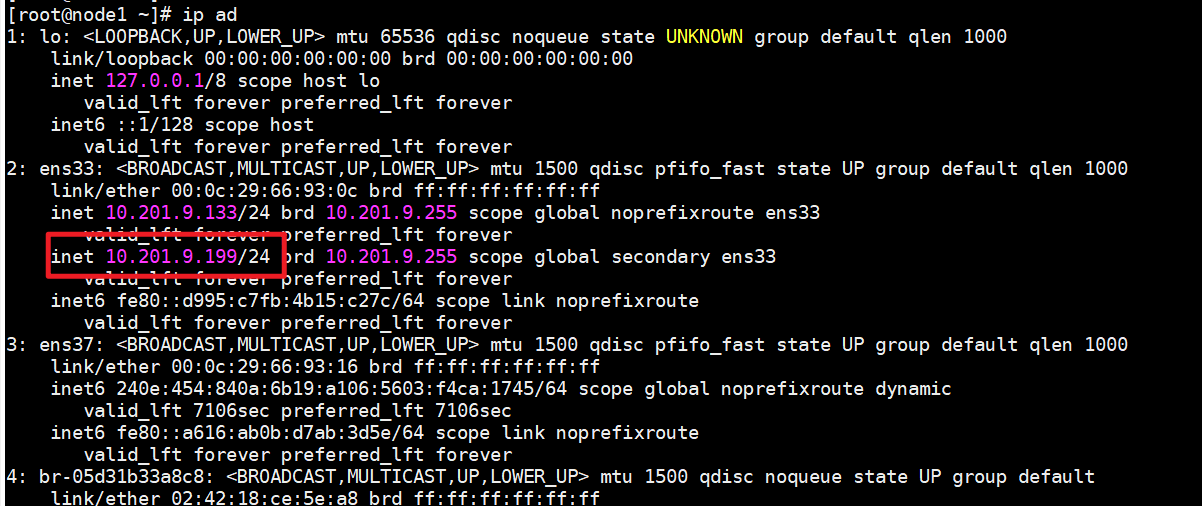
测试
到目前为止我们使用pacemaker创建了一个vip的资源,测试一下,当node1节点挂机之后,node2节点是否还能够通过vip继续接管服务。我这里已经在node1和node2上面都安装了nginx服务,并且为了验证效果都修改了他们的默认访问页。
node1访问如下:
node2访问如下:
在node1节点还是正常运行的时候,我们通过访问vip:10.201.9.199的话显示如下,默认是访问的node1的nginx页面,现在我们将node1网卡停用之后再观察。
停止node1网卡,模拟故障
在node2节点上插件集群状态,可以看到当node1故障之后,vip就飘到了node2节点上了,此时在访问vip看看。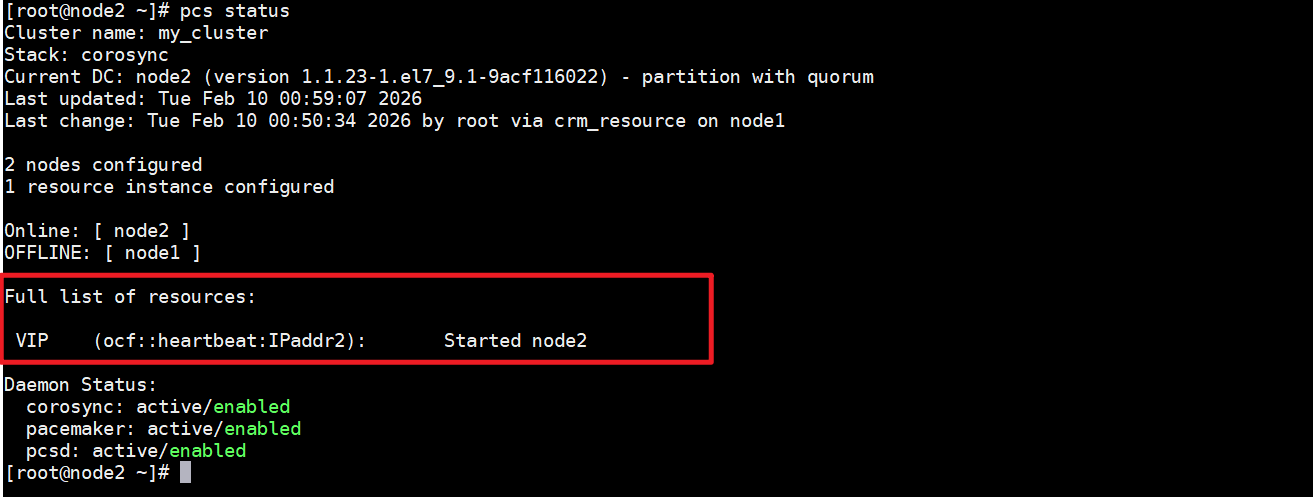
因为vip切到了node2,所以我们访问的也是node2节点上面的nginx页面。
在将node1节点恢复,查看集群状态vip,会自己回到node1节点上。在访问虚拟IP显示的就是node1上面的nginx的内容